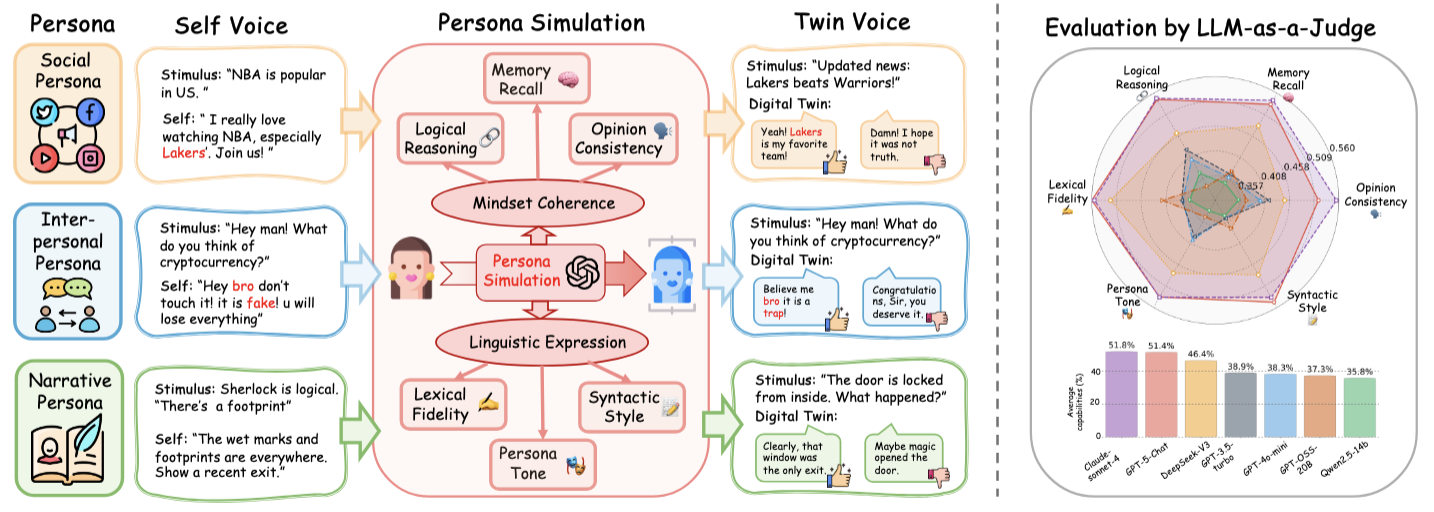
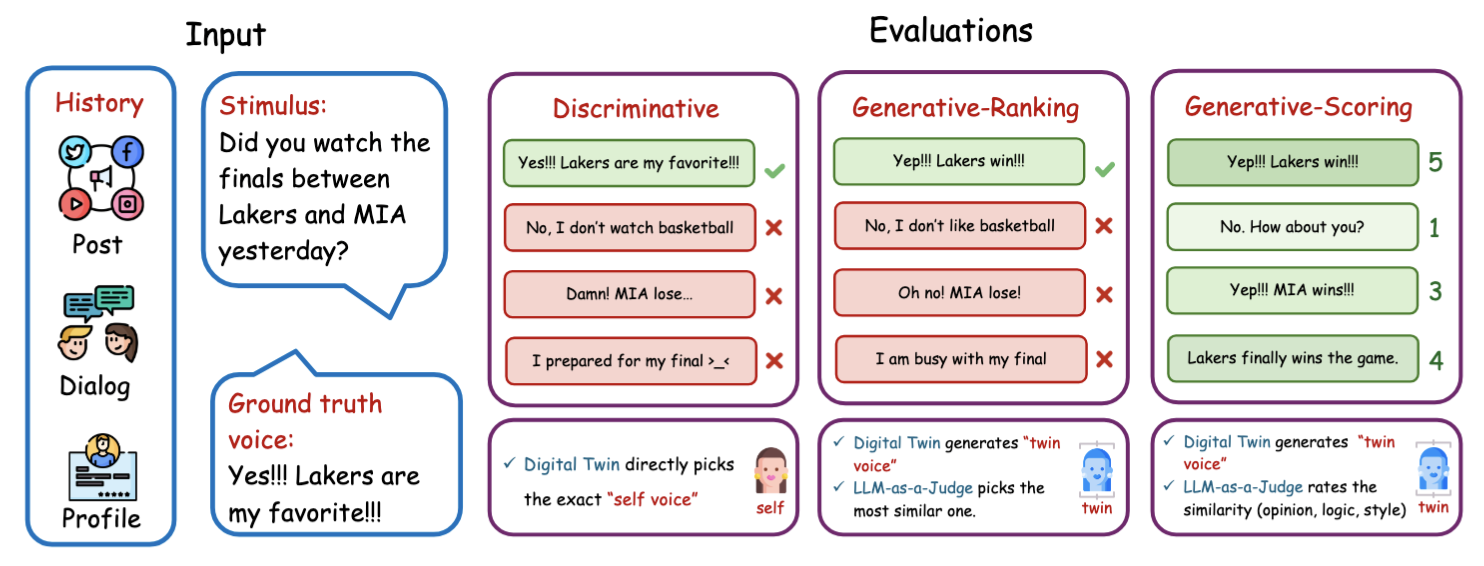
Large Language Models (LLMs) are exhibiting emergent human-like abilities and are increasingly envisioned as the foundation for simulating an individual's communication style, behavioral tendencies, and personality traits. However, current evaluations of LLM-based persona simulation remain limited: most rely on synthetic dialogues, lack systematic frameworks, and lack analysis of the capability requirement. To address these limitations, we introduce TwinVoice, a comprehensive benchmark for assessing persona simulation across diverse real-world contexts. TwinVoice encompasses three dimensions: Social Persona (public social interactions), Interpersonal Persona (private dialogues), and Narrative Persona (role-based expression). It further decomposes the evaluation of LLM performance into six fundamental capabilities, including opinion consistency, memory recall, logical reasoning, lexical fidelity, persona tone, and syntactic style. Experimental results reveal that while advanced models achieve moderate accuracy, they remain insufficient in sustaining consistent persona simulation, especially lacking the capability of syntactic style and memory recall.